
By Ivan Nonveiller & Léandre Larouche
Elucidating the different types of computing in the context of Artificial Intelligence (AI).
In 2009 Google Brain started using Nvidia GPUs to create capable DNNs and deep learning experienced a big-bang. GPUs, well-suited for the matrix/vector math involved in machine learning, were capable of increasing the speed of deep-learning systems by over 100 times, reducing running times from weeks to days. Since then, artificial intelligence has been changing our society at a breathtaking pace. Automated recommendations and suggestions are responsible for around 75% of what people watch on Netflix and more than 35% of what people buy on Amazon. Facebook is using AI to recognize the content of posts, photos and videos and display relevant ones to users, as well as filter out spam. Its application in distributed environments, such as the Internet, electronic commerce, mobile communications, wireless devices and distributed computing continually increased and now provides enormous economic potential both to the industrial and research sectors.
Three types of AI computing
Today, most personal computers with GPU cards can be used for distributed and decentralized computing, solving equations and providing computing power for artificial intelligence. The three main different types of AI computing are centralized, distributed, and decentralized. Let’s compare the three of them briefly before we dive deeper into each of them.
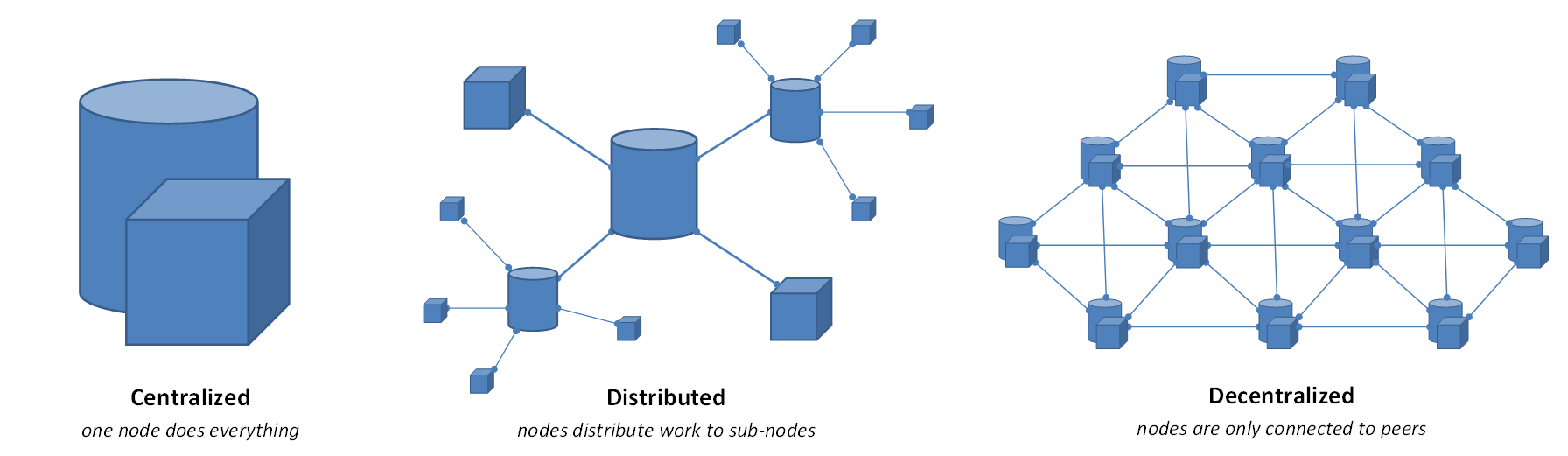
In a centralized environment, all calculations are done on one particular computer system, such as a dedicated server for processing data. In a distributed scenario, however, the calculation is distributed to multiple computers which join forces to solve the task. For example, a large amount of data can be divided and sent to particular computers which, will then make their part of the calculation.
Distributed computing, on the other hand, means that not all transactions are processed in the same location, but that the distributed processors are still under the control of a single entity. You can think about it as a gas station: while you can get your gas from different branches of, say, Shell, the resource is still distributed by the same company.
Decentralized computing, on its end, entails that no one single company has control over the processing. By its very definition, decentralized computing means that the data is distributed among various machines for different computers to perform the tasks. This type of computing takes away the possibility for any party to amass loads of data.
Distributed computing takes an increasingly important role in data processing and information fusion. Industries such as electronic commerce, mobile communications and wireless devices heavily rely on distributing computing to perform the computing tasks it needs in order to operate.
Centralized Computing
A typical example of centralized computing would be NFS (Network File System). There is a single NFS File Server machine that actually hosts all the file system data and meta-data. Client machines run a client-side component (NFS Client) that allows the machines to mount the remote file system locally on respective Operating Systems.
In a centralized scenario, client machines connect to the server computer, otherwise known as the master computer, and submit their request. NFS Client intercepts file system requests corresponding to NFS mount and uses RPC to send them across the network to NFS file server.
The point here is that clients don’t necessarily have to be lightweight. In fact, NFS Clients can be very aggressive when it comes to caching meta-data, and they implement loads of optimizations to reduce the number of round trips to the server. The key concept to understand is that all the NFS Clients are very much dependent on the NFS server machine that hosts the file system data. File system operation requests coming on client machines are not processed locally. The files are sent across the network to the remote file server, so the client machine is very strongly coupled with the server machine where all the file system requests are processed.
Another example of centralized computing would be a web application server that hosts all the business logic, runs the database and so on. Various client machines connect to the web application server and send/receive requests/responses through the HTTP application layer protocol (of course underneath HTTP runs over TCP). It is not the case that clients do not run any kind of software. They are usually thin clients that are mostly responsible for presentation logic, such as displaying results and allowing the user to customize UI. However, all of the core application logic is in the software running on the web application server.
There are major disadvantages to centralized computing, however. These include the single point of failure and limited scalability. If, for example, the server machine goes down, clients might turn out to be useless since there is no remote server to process the requests, and clients themselves do not have enough capabilities to keep up the service in the event of such failure. If the clients are not responsible for running any core logic and strongly depend on the server machine, then availability is completely compromised for such a system in case the server machine fails.
When it comes to scalability, all the core application logic is self-contained in a single server machine. Consequently, the only way we can imagine to scale the system is vertical scaling, by adding more storage, I/O bandwidth and processing power (number of CPUs, number of cores) to the server machine. The more powerful our server machine is, the better the performance of the overall system. The problem is that it is difficult to create, maintain and rely on a single magic computer box that solves all of our problems. Eventually, the attempts to scale up a single machine by adding more hardware may not turn out to be cost-effective.
To remediate to this issue, it might be more reasonable to add another compute node to the system, meaning to scale out—otherwise known as horizontal scaling—by adding another machine with just good enough computing resources. If there is only a single system, and with a given number of resources and processing power, such as the number of cores, there are only so many client requests that can be processed in parallel. During periods of high activity, the single server model will soon turn out to be a bottleneck as it will be difficult to keep up with the influx of concurrent user requests, and the number of requests system can really process.
Distributed Computing
In a distributed computing system, multiple client machines work together to solve a task. Instead of a master computer that outperforms and subordinates all client machines, the distributed system possesses multiple client machines, which are typically equipped with lightweight software agents. In this scenario, all the client machines work autonomously although sharing the information necessary to achieve the goals.
One example of a distributed computing system is that of the SETI Institute, which collects satellite images in an attempt to find extra-terrestrial life and then distribute the large sums of data to computers across that world that analyzes it and sends it back to SETI. The key here is that no single computer machine would be capable of processing such large amounts of data. However, the scalability that distributed computing systems makes it possible.
The most valuable advantage of distributed computing is that it offers near-unlimited scalability and no single point of failure. Unlike in a centralized computing system, the distributed environment can process all SETI ’s data without danger of the operations shutting down due to the failure of one computer. If one client machine fails, the rest of the computing network is safe to continue its operations.
Other benefits of the distributed computing system include the reduced cost of operation as well as increased performance, reliability, and transparency.
Decentralized Computing
In decentralized computing, no single server machine is solely responsible for all the processing. The architecture allows for the distribution of the workload among multiple compute nodes, otherwise known as machines, and each of them is equally capable of servicing requests.
The best example of decentralized computing is the Cassandra data store. In this model, data is stored on multiple nodes, and client requests can come to any node (probably the one that is geographically nearest to minimize the latency). There is not really any single point of failure because the client machines don’t rely on a single server to fulfill all requests. On the contrary, the system comprises multiple nodes which might be still available to process user requests.
The major advantage of decentralized computing is that we can scale out the system by adding more nodes and thus more compute power and fault tolerance. However, the mental model is not easy in decentralized computing. Since now we have more machines, we also have more problems to deal with. In fact, decentralized computing is quite similar to distributed computing in a way. In both decentralized and distributed Ai computing, users typically need to deal with the same set of problems and challenges in both spaces.
Decentralized systems, as one can expect, is prone to cause complex problems such as replica management as well as maintenance of consistency across copies of data and across multiple nodes. Hence, it is important to understand and internalize the fundamental concepts of distributed systems before going about designing a decentralized system. Users should be aware of the well-known challenges in all spaces.
In centralized computing, we have a simple and sweet mental model as there is just a single server machine that does all the jobs, but if it’s gone we are all out of luck
Orion Platform
Orion Platform is a blockchain-based, AI-focused, distributed supercomputing platform established to meet the growing demand for computational power required for complex AI computations. The platform was developed by Nebula AI, a Montreal-based startup that collaborates with Concordia and McGill University.
Orion’s computational supply harnesses existing distributed GPU-based computing resources owned by crypto-mining and gaming companies. Nebula AI is able to buy these companies’ compute power for more than they can earn mining or providing computing power for gaming. At the same time, Nebula AI provides the computing resource to AI companies for less than they pay to traditional compute Suppliers.